

In the industrial world, it is all too common to see a customer who has standardized on managed switches, yet leaves them in the default state. More often than not, these switches go through their entire lives never once having been configured or actually utilized beyond the capability of its counter part that is 1/8th of the cost. In most cases, the managed switch is overkill and an artifact of an over reaching broadly defined specification. But what about the cases that made that specification come about in the first place?
A few years back I was working as the system integrator for a line with 4 tooling vendors at a tier 1 JIT facility. The system had 2 ControlLogix L74 PLC’s, 8 CompactLogix 5370 Series PLC’s, and even a couple of MicroLogix 1400’s. With nearly 100 remote IO devices, and produce / consume tags set to every PLC with one of the L74’s handling part trace ability and communication to the plants MES system. There were over 20 3rd party HMI’s, and a dozen robots. In the beginning as the first sets of equipment were dropped off, everything was fine. We saw all of the equipment running standalone without any issue.
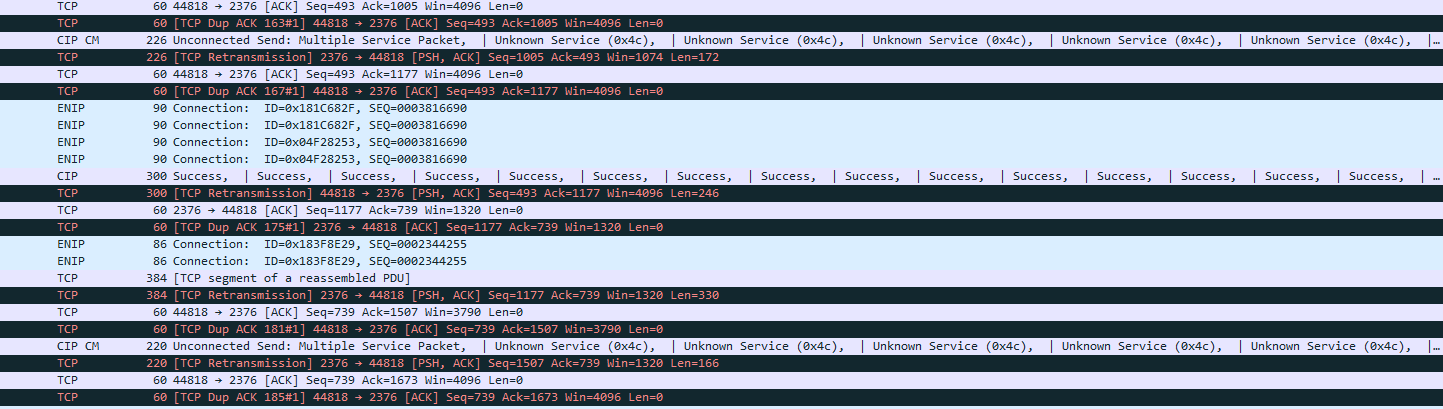
The problems didn’t begin until we began connecting all the networks and configuring the permissives for the part tracking. Firstoff we saw some lag on the barcode readers and a spike on the main PLC’s communication slice. No big deal. Offset the RPI’s of each network device as the integrators had left them all at the default 20ms when shipping. Who needs to check for a barcode update every 20ms? That would call for a queue function in the reader. Added another 10% of the cpu to the comm slice as well. Next up we started to check our messaging. We saw that several of the HMI’s were locking up – they required a power cycle to restore. Within an hour or two, the same HMI’s had locked up again. Over the next few weeks, the tooling suppliers and the plant went back and forth with the manufacturer of the HMI with no real resolution; a few changes in the projects, a few firmware updates. Nothing seemed to make much of a difference. The only thing that had an impact was reducing the number of HMI’s on the network. That’s when I decided to dig into the problem myself. The line had standard unmanaged switches, so I borrowed an 8 port managed from the plant IT staff. I configured port mirroring and tucked it between the main traceability PLC and the primary switch for the line. I configured Wireshark to intercept any traffic with one of the HMI’s addresses and let it rip.

The first thing I noticed was the flood of TCP Retransmission and TCP Dup Ack packets. They were flooding the network! Next was the size of some of these packets, most of them between 200 and 400 bytes. Looking at the data in the packets, we recognized the messages in the alarm banners for the HMI’s. It turns out that these 3rd party HMI’s actually take the text from the PLC instead of just a state number. Then they ignore the configured polling intervals set in the project, and alarms continuously poll the PLC. The timeout set in the device was so short, when there was any congestion on the network, they would attempt a retransmission, and further congest the network. This led to a downward spiral until the device locked up.
Upon providing the packet capture to the manufacturer, they acknowledged the issue and were able to reproduce the problem on their end. After a week without an update, we removed all of the alarm banners and replaced them with multi state text boxes. The line is running without issue (here at least) to this day!